Flow의 수집(Collect) 최적화
병합 (conflation)

어떤 플로우가 연산의 일부분이나 연산 상태의 업데이트를 방출하는 경우 방출되는 각각의 값을 처리하는 것은 불필요 하며, 대신에 최신의 값 만을 처리하는 것이 필요할 것입니다.
한 번 시작된 데이터 소비는 끝날 때 까지 하고 데이터 소비가 끝난 시점에서의 가장 최신 데이터를 다시 소비하는 것입니다.
, conflate 연산자를 사용하여 수집기(collector)의 처리가 너무 느릴 경우 방출 된 중간 값들을 스킵 할 수 있습니다.
val time = measureTimeMillis {
foo()
.conflate() // conflate emissions, don't process each one
.collect { value ->
delay(300) // pretend we are processing it for 300 ms
println(value)
}
}
println("Collected in $time ms")
코드를 보면 처음 수가 여전히 수집(collect)처리 중인데 두 번째와 세 번째 수가 방출(emit) 됨을 확인할 수 있습니다. 그래서 두 번째 수는 스킵되고 가장 최근 값인 세 번째 값이 수집기로 전달 됩니다.
1
3
Collected in 758 ms
값의 병합 (Conflation) 은 방출과 수집이 모두 느릴 경우 처리 속도를 높이는 방법 중 하나 입니다. 이것은 중간 값들을 삭제 함으로써 이를 수행합니다.
최신 값 처리 (Processing the latest value)

또 다른 방법은 새로운 값이 방출될 때 마다 느린 수집기(collector)를 취소하고 재시작하는 것입니다.
이를 위해서 xxx 연산자들을 위해 연산자마다 xxxLatest 연산자가 존재하며, 이 연산자들은 새로운 값이 방출되면 그들의 코드블록을 취소합니다.
그림과 같이 데이터 발생 시간 사이의 간격보다 데이터를 처리하는 suspend fun이 수행하는 시간이 오래 걸릴 경우, 새로 들어온 데이터는 계속해서 소비되지 못합니다.
즉, 이런 상황에서 collectLatest를 쓸 경우 중단 데이터를 하나도 얻지 못하고 마지막 데이터만을 얻을 수 있습니다.
이전 예제에서 conflate 를 collectLatest 로 변경해 봅시다
val time = measureTimeMillis {
foo()
.collectLatest { value -> // cancel & restart on the latest value
println("Collecting $value")
delay(300) // pretend we are processing it for 300 ms
println("Done $value")
}
}
println("Collected in $time ms")
collectLatest 의 코드 블럭이 300ms를 소모하고 새로운 값들은 매 100ms 마다 방출되기 때문에,
우리는 이 블럭이 매 값에 대해서 실행 됨을 확인할 수 있으며, 마지막 값에 대해서만 끝까지 수행 됨을 확인할 수 있습니다.
Collecting 1
Collecting 2
Collecting 3
Done 3
Collected in 741 ms
다중 플로우 합성 (Composing multiple flows)
다중 플로우를 합성하는 방법은 여러가지가 있습니다.
merge
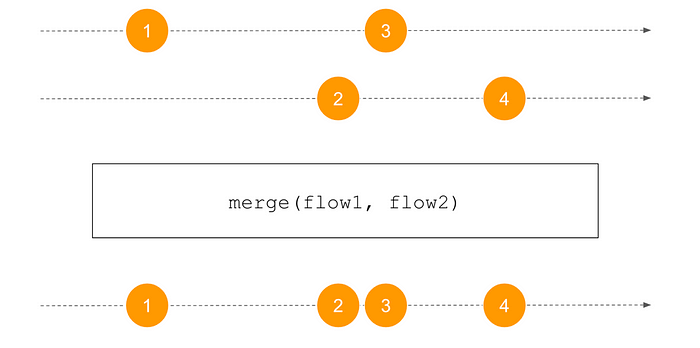
val nums = (1..3).asFlow() // numbers 1..3
val strs = flowOf("one", "two", "three")
merge(nums, strs)
.collect { println(it) } // collect and print1 one two three 2 3
Zip

코틀린 표준 라이브러리의 Sequence.zip 확장 함수와 동일하게, 플로우에도 두개의 플로우들의 값들을 병합하는 zip 연산자가 있습니다.
val nums = (1..3).asFlow() // numbers 1..3
val strs = flowOf("one", "two", "three") // strings
nums.zip(strs) { a, b -> "$a -> $b" } // compose a single string
.collect { println(it) } // collect and print
위 예제의 출력결과는 다음과 같습니다.
1 -> one
2 -> two
3 -> three
Combine

어떤 플로우가 어떤 연산이나 상태의 최근 값을 나타낼 때, 우리는 그 플로우의 최근 값에 추가 연산을 수행하거나 또는 별도의 업스트림 플로우가 값을 방출할 때마다 다시 그 추가 연산을 수행해야 할 수 있습니다.
이와 관련된 연산자들을 combine 이라 부릅니다.
예를 들어, 이전 예제에서의 수들을 300ms 마다 업데이트 하고, 문자열들은 400ms 마다 업데이트 되도록 변경한 후 zip 연산자를 이용하여 이들을 하나의 결과로 만들면 여전히 동일한 결과를 400ms 마다 출력합니다
(가장 느린 Flow 에 맞추어서 수행됨).
우리는 이 예제에서 onEach 중간 연산자를 사용하여 각각의 항목들을 지연시킴으로써 방출 코드를 더 가독성 있고 간결하게 만들 것 입니다.
val nums = (1..3).asFlow().onEach { delay(300) } // numbers 1..3 every 300 ms
val strs = flowOf("one", "two", "three").onEach { delay(400) } // strings every 400 ms
val startTime = System.currentTimeMillis() // remember the start time
nums.zip(strs) { a, b -> "$a -> $b" } // compose a single string with "zip"
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
이 예제에서 우리가 zip 연산자 대신에 다음과 같이 combine 연산자를 사용한다면,
val nums = (1..3).asFlow().onEach { delay(300) } // numbers 1..3 every 300 ms
val strs = flowOf("one", "two", "three").onEach { delay(400) } // strings every 400 ms
val startTime = System.currentTimeMillis() // remember the start time
nums.combine(strs) { a, b -> "$a -> $b" } // compose a single string with "combine"
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
우리는 zip 연산자를 사용했을 때와는 상당히 달라진 다음과 같은 결과를 볼 수 있습니다.
결과를 보면 nums 나 strs 플로우로부터 방출이 일어날 때마다 다른 플로우의 최신값을 가지고 병합하여 출력이 되었습니다.
1 -> one at 452 ms from start
2 -> one at 651 ms from start
2 -> two at 854 ms from start
3 -> two at 952 ms from start
3 -> three at 1256 ms from start
플로우 플래트닝 (Flattening flows)
플로우는 비동기로 수신되는 값 들의 시퀀스를 나타냅니다. 그러므로 어떤 플로우에서 수신되는 일련의 값 들이 다른 값 들의 시퀀스를 요청하는 플로우가 되는 일은 자주 발생합니다.
예를 들어, 안드로이드에서 API 호출을 통해 얻은 Flow에서 방출된 아이템을 바탕으로 또 다른 비동기 API를 호출하여 새로운 Flow를 생성하는 상황을 들 수 있습니다.
다음과 같이 500ms 간격으로 두개의 문자열을 방출하는 플로우를 정의 해보겠습니다.
fun requestFlow(i: Int): Flow<String> = flow {
emit("$i: First")
delay(500) // wait 500 ms
emit("$i: Second")
}
이제 우리는 세개의 정수를 방출하는 플로우를 가지고 각각의 정수가 방출될 때마다 다음과 같이 requestFlow 를 호출합니다.
(1..3).asFlow().map { requestFlow(it) }
우리는 위 작업의 결과로 수신한 값 들에 추가 처리를 위해서 플래트닝이 필요한 플로우들의 플로우를 얻게 됩니다 (Flow<Flow<String>>). 컬렉션들과 스퀀스들은 이를 위해 flatten 과 flatMap 연산자들을 가지고 있습니다.
하지만 플로우는 그 자체의 비동기 특성으로 인해서 다른 모드의 플래트닝이 필요하며 플로우를 위한 플래트닝 연산자들이 별도로 정의 되어 있습니다.
📖 flat vs mat vs concat
1. flat
Kotlin Collection에도 유사한 네이밍을 갖는 flatten이라는 메서드가 있습니다. flatten은 Collection 안에 Collection이 들어있는 중첩된 형태의 Collection을 펼쳐 하나의 Collection으로 만들어주는 역할을 합니다.
이 원리를 Flow에도 적용하면 이해하기 쉽습니다. 즉, 중첩된 여러 개의 Flow를 하나의 Flow로 만들어준다는 의미입니다.
2. map
개발을 하다보면 map은 정말 많이 사용합니다. 보통 리스트 변환을 할 때 사용하게 되는데, 리스트 내의 각각의 아이템들을 변환 (transform)하여 새로운 아이템으로 mapping시킬 때 많이 사용합니다.
동일하게 Flow에서도 발행부에서 발행하는 데이터들에 대한 변환이 필요할 때 사용할 수 있습니다.
3. concat
concat이라는 단어도 익숙하신 분들이 많을 것입니다. 보통 concatenate의 약어로 많이 사용되고, 프로그래밍에서는 “순차” 라는 한글로 많이 쓰인다고 합니다. 문자열 연산으로 생각해본다면 “눈"과 “사람”을 “눈사람"으로 연결시켜주는 역할을 한다고 이해할 수 있습니다. Android에서도 이와 유사한 ConcatAdapter가 존재합니다.
이 원리를 Flow에 적용해본다면, 여러 개의 Flow를 하나의 Flow로 만들어주는 것으로 이해할 수 있습니다.
flatMapConcat

연결(Concatenating) 모드는 flatMapConcat 과 flattenConcat 연산자들에 의해 구현됩니다.
이 연산자들은 시퀀스에 정의된 비슷한 유형의 연산자들과 가장 유사하게 동작하는 연산자들 입니다.
이 연산자들은 다음 예제가 보여주듯이 다음 Flow의 수집을 시작하기 전에 현재 Flow가 완료될 때까지 기다립니다.
따라서, flatMapConcat을 사용하게 되면 각 입력을 한번에 하나씩 처리하게 되어 순서를 보장할 수 있게 됩니다.
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapConcat { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
flatMapConcat 연산자의 순차적 특성은 출력 결과를 통해 확실히 확인할 수 있습니다.
1: First at 121 ms from start
1: Second at 622 ms from start
2: First at 727 ms from start
2: Second at 1227 ms from start
3: First at 1328 ms from start
3: Second at 1829 ms from start
출력된 로그에서도 확인할 수 있듯이 flowA에서 방출하는 Flow를 requestFlow를 통해 map 연산을 수행한 후 flattenConcat을 하게 되면 순서를 보장한 상태로 collect하게 됩니다.
flatMapConcat을 사용하면 동기적으로 스트림을 결합할 수 있게 됩니다. 이로 인해, 오래 걸리는 연산이 Upstream에서 transform 될 경우 최종적으로 Flatten된 데이터를 수집하는데 오랜 시간이 걸릴 것입니다.
flatMapMerge
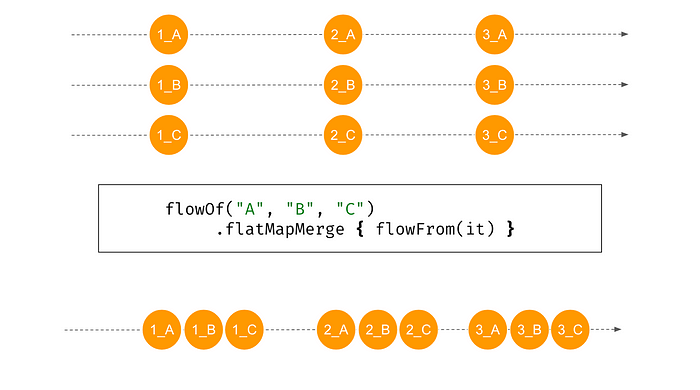
flatMapConcat은 동기적 연산을 수행하기 때문에 map연산에 오랜 시간이 걸리는 경우 최종 Flatten된 데이터를 수집하는데 오래 걸리는 단점이 있습니다. 이러한 단점을 flatMapMerge를 사용하면 해결할 수 있습니다.
flatMapMerge는 모든 들어오는 플로우들을 동시에 수집하고 그 값들을 단일 플로우로 합쳐서 값들이 가능한 빨리 방출되도록 하는 모드입니다.
flatMapMerge은 concurrency 파라미터를 지원하며 이를 통해 동시에 수집 가능한 플로우의 개수를 제한할 수 있습니다. (기본 모드는 DEFAULT_CONCURRENCY 입니다.)
기본적으로 16개의 동시성을 지원합니다. (만약 concurrency가 1일 경우는 flatternConcat으로 동작합니다.)
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapMerge { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
flatMapMerge 의 동시성 특성은 출력 결과에 명백히 드러납니다.
1: First at 136 ms from start
2: First at 231 ms from start
3: First at 333 ms from start
1: Second at 639 ms from start
2: Second at 732 ms from start
3: Second at 833 ms from start
위 출력 결과를 통해 flatMapMerge 가 코드 블록(예제에서는 { requestFlow(it) })은 순차적으로 호출하지만 그 결과 플로우들은 동시에 수집한다는 것을 확인할 수 있습니다.
즉, Flow의 각각의 데이터가 순서에 따른 flatten을 대기하지 않고 주어진 concurrency만큼 동시에 flatten될 수 있는 것을 의미합니다.
따라서, flattenMerge을 하게 되면 순서 보장 없이 빠른 순서대로 collect하게 됩니다.
왜냐하면 flatMapMerge는 각 Flow의 발행을 동시에 처리하기 때문에, 첫 번째 Flow가 발행한 값이 두 번째 Flow의 값보다 나중에 도착할 수도 있기 때문입니다.
flatMapConcat과 달리 flatMapMerge를 사용하면 비동기적으로 스트림을 결합할 수 있다는 장점이 있게 됩니다.
flatMapLatest

flatMapLatest는 앞서 살펴본 flatMapConcat, flatMapMerge와 크게 다르지 않지만 쓰임새가 조금 다릅니다. collect와 collectLatest의 차이점을 알고 계신다면 이름만으로도 이미 이해하셨다고 봐도 무방합니다.
flatMapLatest도 두 Flow를 flatten하는 것은 동일합니다. 앞서 살펴본 연산자들의 특징을 다시 봐보겠습니다.
- flatMapConcat : Flow가 갖는 delay 만큼 모두 대기하여 순차적으로 flatten 진행
- flatMapMerge : delay 하지 않지만 발행하는 모든 데이터를 빠르게 flatten 진행
두 연산자와 달리 flatMapLatest는 방출된 데이터들을 추적하여 새로운 데이터가 방출되면 직전 데이터의 방출을 취소합니다. 즉, 최신 데이터만 추적하게 됩니다.
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapLatest { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
이 예제의 다음과 같은 출력 결과를 통해 flatMapLatest 가 동작하는 원리를 이해할 수 있습니다.
1: First at 142 ms from start
2: First at 322 ms from start
3: First at 425 ms from start
3: Second at 931 ms from start
flatMapLatest 는 새 값이 방출되면 그 실행 블록(이 예제에서는 { requestFlow(it) }) 전체를 취소합니다.
이번 예제 에서는 별 차이를 확인할 수 없는데 그 이유는 requestFlow 호출 그 자체는 빠르며, 중단되지 않고, 취소될 수도 없기 때문입니다. 만약 우리가 이 부분에 delay 와 같은 중단 함수를 사용한다면 flatMapLatest 의 특성을 더 명확히 확인해 볼 수 있습니다.
정리
- flatMapConcat 은 발행 순서와 발행 갯수를 보장합니다.
- flatMapMerge은 발행 갯수는 보장하지만 발행 순서는 보장하지 않습니다.
- flatMapLatest은 발행 순서는 보장하지만 발행 갯수를 보장하지 않습니다.
Flow 변환 Operator
fold

fold()는 문자, 숫자 값 등을 누적 처리 하기 위한 Operator입니다. fold()을 이용하여 누적합, 누적값, 팩토리얼 연산 등을 간단하게 처리 할 수 있습니다.
Kotlin Collection 함수에서도 동일한 개념으로 제공하고 있습니다.
Flow의 fold()는 collect()와 같은 Flow를 실행 시키는 터미널 operator입니다.
그래서 선언과 동시에 Flow를 실행 시킵니다.
문자, 숫자 값 등을 누적 처리 하기 위한 또 다른 방법으론 scan() 이 있습니다.
scan
fold() 는 누적 처리 + Flow 실행을 갖고 있습니다. scan() 은 값을 누적 처리 하기 만을 위해 사용합니다.

scan()은 suspend block에 직전값과 현재값을 전달합니다.
이 속성을 이용해서 방출되는 데이터를 하나의 리스트로 관리 시킬 수 있습니다.
val userStateFlow: Flow<User> = userChangesFlow
.scan(user) { acc, change -> user.withChange(change) }
// 별도로 리스트에 저장할 필요 없이, 계속 리스트에 방출값을 저장할 수 있음
val messagesListFlow: Flow<List<Message>> = messagesFlow
.scan(messages) { acc, message -> acc + message }
참고자료
Kt.Academy Kotlin Coroutines Deep Dive Summary 7부 — Flow Operator
본 게시글은 Kt.Academy의 Kotlin Coroutines DEEP DIVE의 요약본입니다.
medium.com
https://medium.com/hongbeomi-dev/kotlin-coroutine-flow-ac07cfdca42d
Kotlin coroutine flow
코틀린 코루틴 플로우 공식 블로그 [번역]
medium.com
[Coroutine Flow] conflate를 이용해 최신 데이터 collect 하기
collectLatest를 이용한 최신 데이터 collect의 한계점 그림1과 같이 데이터 발행 시간 사이의 간격보다 데이터를 처리하는 suspend fun이 수행하는 시간이 오래 걸릴 경우, 새로 들어온 데이터는 계속해
kotlinworld.com
Kotlin Coroutine Flow 총정리 part3 # launchIn
지난 글에 이어서 part3에서는 Coroutine의 Flow에 대해서 정리해 보도록 하겠습니다.지난 part1과 part2는 아래 링크를 참조해주세요.>> Kotlin Coroutine 총정리 part1 # launch, async, Context, Job, CoroutineScope >> Kot
developer88.tistory.com
(Android) Flow Flattening 연산자 톺아보기
flatMapConcat, flatMapMerge, flatMapLatest
medium.com
'Android > Flow' 카테고리의 다른 글
| [Android] Cold Flow와 Hot Flow (1) | 2025.02.17 |
|---|---|
| [Android] ChannelFlow와 CallbackFlow (0) | 2025.02.16 |
| [Android] 코루틴 Flow를 활용한 성능 개선 - 다중 요청 처리 (flatMapMerge) (0) | 2025.02.16 |
| [Android] 플로우(Flow)란? - Deep Dive (1) | 2025.02.15 |
| [Android] Flow 기초 (0) | 2023.06.27 |



